PHISH.NET SHOW RATINGS, PART 4: CAN RATER WEIGHTS IMPROVE THE ACCURACY OF SHOW RATINGS?
[We would like to thank Paul Jakus (@paulj) of the Dept. of Applied Economics at Utah State University for this summary of research presented at the 2024 Phish Studies Conference. -Ed.]
This is the fourth and final blogpost regarding the current rating system. Previous posts can be found here, here and here.
Post #2 showed how two metrics—average deviation and entropy—have been used by product marketers to identify anomalous raters; Post #3 showed how anomalous users may increase bias in the show rating. Many Phish.Net users have intuitively known that anomalous raters increase rating bias, and have suggested using a rating system similar to that used by rateyourmusic.com (RYM). RYM is an album rating aggregation website where registered users have provided nearly 137 million ratings of 6.2 million albums recorded by nearly 1.8 million artists (as of August 2024).
Similar to Phish.Net, RYM uses a five-point star rating scale but, unlike .Net, an album’s rating is not a simple average of all user ratings. Instead, RYM calculates a weighted average, where the most credible raters are given greater weight than less credible raters. Weights differ across raters on the basis of the number of albums they have rated and/or reviewed, the length of time since their last review, whether or not the reviewer provides only extreme ratings (lowest and/or highest scores), and how often they log onto the site, among other measures. These measures identify credible reviewers and separate them from what the site describes as possible “trolls”. Weights are not made public, and the exact details of the weighting system are left deliberately opaque so as to avoid strategic rating behavior.
So, if assigning different weights to raters works for RYM, will they work for Phish.Net?
Following RYM, each of the 16,452 raters in the Phish.Net database was assigned a weight, ranging between zero and one, based on cutoff values for average deviation, entropy, and the number of shows rated. Instead of calculating a simple average show rating, where all raters have equal weight, my alternative show ratings are weighted averages. Differential weights assure that users believed to provide greater informational content and less statistical bias contribute more to the show rating than those believed to have less content and more bias (anomalous raters).
The first alternative system is called the “Modified RYM” (MRYM) because it represents my best effort to match the RYM system. MRYM is also the “harshest” of the weighting alternatives because it assigned the smallest weight (0.0) to those with zero entropy (where the expected average value of information is zero) and to those with exceptionally high deviation scores (top 2.5%). Low entropy users were assigned a weight of 0.25, and those who had rated fewer than 50 shows were given a weight of 0.5. (If a rater fell into more than one category they were assigned the smallest weight.) All others were assigned full weight (1.0). Four other weighting systems (“Alternative 1” through “Alternative 4”) gradually relaxed these constraints, giving raters increasingly larger weights relative to the MRYM, but less than the equal weights of the current system.
To summarize, we now have six different rating estimates for each show: the current (simple mean) rating with equal weights, and show ratings from five different weighted alternatives. The true value of the show rating remains unobservable, so how do we know which system is best?
My previous research ( https://phish.net/blog/1539388704/setlists-and-show-ratings.html ) demonstrated that show ratings (with equal rater weights) are significantly correlated with setlist elements such as the amount of jamming in a show, the number and type of segues, the relative rarity of the setlist, narrative songs, and other factors. If the deviation and entropy measures have successfully identified the raters who contribute the most information and least bias, then weighted show ratings should be even more correlated with show elements relative to the current system. Technically, this analytical approach is a test of convergent validity.
Using setlist data from 524 Modern Era shows (2009-2022), regression analysis demonstrates that all of the weighted show ratings exhibit better overall statistical properties relative to the current system (see the chart below.) Each of the weighted show ratings systems has better overall statistical significance (F-statistic) and correlates more strongly with show elements (Adjusted R-square) than the current system. Further, the prediction error (root mean square error) is marginally smaller.
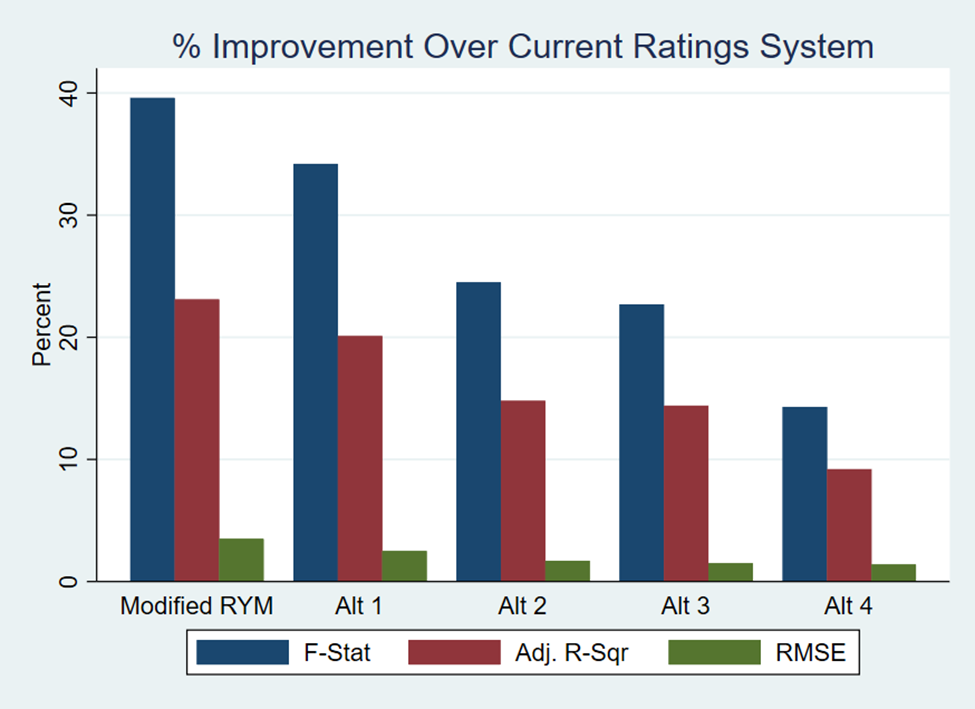
The weighted ratings that perform best are the MRYM and its closest alternative, “Alt 1”, both of which give relatively low weights to anomalous raters and achieve the largest improvements over the current rating system.
Further work is still needed. For example, the cutoff values for the deviation and entropy metrics were rather arbitrary, as were the values for the weights. Testing cutoff and weight assumptions is not difficult, and the conclusion is likely to remain: weighted show ratings are statistically superior to the current system.
Will weighted show ratings come to Phish.Net in the future? I hope so, but the coding effort needed to get everything automated may prove challenging. For now, assessing the performance and stability of .Net’s new coding architecture remains the top priority, after which we can ask the coders to think about weighted show ratings.
Comments
You must be logged in to post a comment.
 The Mockingbird Foundation
The Mockingbird Foundation
The discussion thread can be found at This Link.
1. Dropping raters with exceptionally high deviation scores will mechanically increase R2 and decrease RMSE, so I would be careful to only use those metrics when comparing weighting schemes that treat high-deviators the same.
2. Using the F stat is a very clever metric. I'm sure you're aware it's imperfect for these purposes, but still it's a really nice way to frame the issue, IMHO. Bravo!
3. I would be curious to see a graph of avg rating by year, comparing the different weighting schemes. Which years win? Which lose? (Ideally extend back to 1.0)
4. You've probably thought of this, but a middle ground option between doing nothing and doing full-on real-time adjusted weights would be to generate the weights at regular intervals, e.g. monthly. This may be easier coding-wise, although of course it would require some human labor with each update. (The idea being that any new accounts created in between weighting updates would get an initial weight of zero or close to zero.)
I haven't done this for every year, but here's a couple of things that aim in that direction. For all of the weighted averages (two of which are depicted below), the distribution remains left-skewed, but is squished from the top. There's a bit more mass in each tail, and the overall mean rating (the mean for all shows) actually increases. This graph includes shows from all eras.
As for the year-by -year thing, I've done it for selected years--one from each era (Modern, 2.0., and 2 x 1.0). There was no real rhyme or reason as to which years were selected; mostly they seemed like interesting years, and I had the Phish Studies Conference deadline bearing down on me.
This is exactly how RYM handles its weights.
I just think that since we are seriously considering a change to ratings, then we should also consider letting users have more than 5 options to differentiate shows.
Having to rate a good Phish show as a 2 is not something that appeals to many fans i'm sure. With the 5 star rating system, how often are users really giving the 20-40th percentile shows a 2? I would guess, almost never.
I'm not an expert, I am just going by how I feel about things. I hope those who have all the data make the correct decisions about how to proceed. The ideas presented in this article seem like a step in the right direction.
Your Figure 9 looks promising. That's a more plausible distribution of show ratings, rather than the bimodal distribution under the current rating system.
One other idea I just had, which would address the point that @zeron and others have made... We see users mostly rating shows 4 or 5 rather than using the full range. Personally I think this is fine. However, if we want to "spread out" the resulting scores, the site could display each show's percentile ranking, in addition to (or as an alternative to) its avg star score.
So --- just making numbers up --- a given show might say: "Show rating: 3.914, 42nd percentile among all Phish shows"
That way we would have an absolute measure as well as a relative measure of each show's quality.
If we believe to know the majority of setlist elements that typically correlate to a rating, would it make sense to list those elements for a user to individually rate when they go to rate a show? Subsequently a formula could crunch those numbers together to generate an "overall rating". Personally, I think I would stop and think twice about each category and probably be less impulsive with my rating after attending a show. Yes, it could drive some people away from rating due to the "survey-ness" of the approach, but at least you're able to understand and measure the impact of a rating based on those elements.
I am happy to help if you like the idea and need a volunteer. I have 20+ years of experience in eCommerce and data analysis.
Similarly, we don't know whether a mathematical sum of ratings applied to each of the identified elements would be reliably representative of a given fan's global impression of a given show.
Ultimately it might be impossible to deviate from a simple average of user ratings, where each rater gives a single rating to a given show, without imposing distortive biases and introducing new layers of systematic inaccuracy.
On another note, I like @Lysergic's idea above - keep the current 5 point scale but add percentile. That would keep everyone happy!
I think everything @paulj wrote is incredibly interesting. I also worry that by codifying the ratings system, we’re baking in a lot of a lot of rules about how you can properly enjoy Phish. The ratings are an incredibly helpful way to find great shows to listen to; taking them more seriously than that kind of discounts that people enjoy Phish for a ton of different reasons. >5% of reviews are potentially from fluffers - just clean out bots and maybe purge the most egregious review scores and call it a day?
“If the deviation and entropy measures have successfully identified the raters who contribute the most information and least bias, then weighted show ratings should be even more correlated with show elements relative to the current system. Technically, this analytical approach is a test of convergent validity.”
Who is to say that a poorly performed but major “bust out” always merits a higher rating, for example? The Baker’s Dozen Izabella was a huge bust out but pretty poorly performed. The first Tela I ever saw made me depressed because of how not like the 90s it was (subsequent ones were much better).
It seems to me the entire endeavor to ascertain a “reliable” rating system described in these series of posts itself presupposes that (1) there is an objective, verifiable way to measure the quality of a show and (2) the rating system should be used for that purpose instead of to reflect the aggregate of the assessments of the people who have heard or experienced the show.
I would say both of those assumptions are wrong, and the whole effort is misguided in that sense.
To me, a useful rating system should tell us (1) what did the people who attended this particular show think (ie, the fun factor) and (2) what do the people who regularly listen to and attend Phish concerts think about the quality of this show (ie, replay quality). (If someone went to a show and got puked on and had a bad time, it’s not “wrong” for him to rate it poorly.)
Distinguishing ratings on those two dimensions would help a lot.
A third may be to distinguish quality of jamming from quality of composed performances. For me there are shows where the jamming is better and others where the compositions are played perfectly, and they don’t always coincide.
Allowing a 10 point rating scale would also help for the reasons mentioned above—most phish shows are amazing, and no one wants to rate one a 3/5. 6 or 7 out of ten seems more generous even when it technically is not. In my view most phish shows should be in the 6-10 out of 10 range.
How to verify that the ratings submitted by users reflect genuine beliefs is a separate issue and I applaud the thinking to develop some sort of control. Weighting rankings could be one way although similar to others here it rubs me the wrong way.
I'm personally most interested in this data just to understand the human behavior behind it. And the solutions I most like are things that prevent people from gaming the system (i.e. fake/dupe accounts).
One thing that would really nicely augment the ratings system would be a curation system that lets people build and collaborate show lists based on criteria defined by phish.net members (i.e. Top 1.0/2.0/3.0, top SoaMelts, etc). Kind of like we do in the threads, but in a more permanent structure. N00b100's long posts could take on a permanent life of their own.
Regardless of when I respond, ALL comments from the blogposts and the discussion thread will be summarized for the .Net Overlords. My goal is to get that ready by mid- to late-September, and I'll get a PDF copy available to anyone netter who requests it.
What can I say? People don't like IT when you tell it like it is. Sorry for the truth bomb. There was nothing wrong with the system, but apparently needs more thought put into this than anything else in life. Power! All about the power!
Who are the people who are like, “Oh thank god that rating was adjusted, I really felt like it was wrong”?
The most valuable thing that could come out of this work is finding the users who have a bunch of bots pounding the ratings.
https://forum.phish.net/forum/show/1379933076#page=1
Right on. Can't up vote you, but I tried. I agree with your analysis. Much more in tune with the band than small fan base that worries about such things as the ratings.
RATING SCALE ~ Rotten Tomatoes uses a 5-Star rating system that includes half-stars, effectively making a 10-point scale, allowing for more nuanced ratings. When selecting a rating, RT also provides a broad definition of what each point "means," ie with a 2.5-star rating suggested to be "Not Bad, but Not My Favorite" and 3.5-star rating suggested to mean "Worth a Watch."
These "meanings" may be problematic in data collection (I'm not sure, would love to hear thoughts) and would almost certainly be contentious in the context of Phish show ratings, but for RT I suspect they are at least broad enough to allow for some basic guidance without overly constricting reviewers' ratings. For RT, they also point toward the "value" of ratings being primarily intended to help potential viewers decide whether or not to watch a given movie.
In this Phish context, beyond community consensus of the all-time "best" shows, the "value" of ratings could potentially be construed to be helping fans find quality shows to listen to. However, those two things---"best" and "quality listening"---probably generally correlate, but aren't always the same (ie for highly-theatrical shows whose entertainment value might not be fully represented "on tape").
Regardless of "defining" the scale, I do think a 10-point scale would be better for Phish.net.
RATING TIMING ~ Rotten Tomatoes does not allow audience ratings until after the theatrical release of a film. There may be an additional lag, I'm not sure (and streaming releases complicate things). For Phish.net, I'd suggest a 24-hour delay, from end of show time, before ratings open. You know, sleep on it.
SHOW TRACKING ~ Somewhere over the years, probably in the forums, I've gotten the sense that some fans use ratings to track the shows they've attended (or even just those they've listened to, for the completists out there), which could explain why all ratings from a given user are 5-star (or any other single value). This possible usage pattern may also inform the prospect of implementing a weighted scoring system.
This may simply be convenience, because the "I was there!" button is buried in the "Attendance" tab. Making personal attendance tracking more accessible (perhaps elevating it alongside the ratings input) could ultimately improve the ratings data. Attendance could also be better nuanced as "Engagement" and could include "listened to," "livestreamed," etc, thus expanding individual fans' personal tracking and stats, while also giving more overall site data.
If a weighting system is implemented, I like @jr31105's suggestion of making both weighted and unweighted scores available to users. Cheers!
The sampling and response biases inherent in Phish.Net ratings are such that, short of full-blown, well-designed survey of all Phish fans, we will never get the methodology "exactly right". What I'm trying to do is identify the low hanging fruit: are there biases inherent in the ratings data that we can fix relatively easily?
Obviously, I think we can correct for some of the biases we all know are in the data. My approach has been to review the extensive academic literature to see what others have done when they have encountered the same issues as .Net. I'm not proposing anything new here; I am simply advocating that we do what others have done.
As for ranking of shows, show ratings estimated to the third decimal is highly likely to be false precision--even if a weighting system is adopted! Weights will reduce the overall bias in the data, but not eliminate it. So, it is NOT ME who is arguing whether Mondegreen N3 is #5 or #20 or whatever.
Since May of 2010 I've seen countless complaints about biased ratings, and all I'm saying is, "Hey, we can fix at least some of that shit."